Posts Tagged ‘culture’
“O bliss of the collector, bliss of the man of leisure!… Ownership is the most intimate relationship one can have to objects. Not that they come alive in him; it is he who comes alive in them.”*…

Readers may have seen news of the sale of “Gus,” a T. Rex skeleton that fetched a record $50,130,000 at Sotheby’s in New York last Tuesday. It’s part of a trend.
Devon Pendleton reports that dinosaurs have become an asset class for billionaires, with alarming implications for science… and, unsurprisingly, the market is about as orderly and genteel as a starving T. Rex. She uses a different recent sale, one that went pear-shaped, as an example…
It was supposed to be an unprecedented sale for the world’s wealthiest collectors. Shen, a Tyrannosaurus rex, was set to be the first of its kind ever sold at auction in Asia. The reconstructed creature, whose name means “godlike” in Chinese, was tens of millions of years old and longer than a city bus, frozen midstep with its massive skull cocked, jaws agape, as if ready to snatch up an onlooker. Christie’s was auctioning off Shen in November 2022, alongside works by Picasso, and it was expected to sell for $15 million to $25 million.
Dinosaur skeletons had recently become a hot new asset class, coveted by the ultrarich, not unlike sports franchises or Fabergé eggs. They offered a mix of glamour and primal appeal to a certain type of high-net-worth buyer—someone who might find the conventional art market fussy or convoluted but couldn’t deny the allure of a T. rex. “It could gobble you up in one bite. It’s just an amazing creature,” says billionaire Dan O’Dowd, who bought his T. rex, Samson, for a bargain $600,000 in 2009. “It’s the best trophy kind of thing you could own.”
Two years before the Shen auction, Christie’s had sold a T. rex named Stan, said to be one of the most complete and best-preserved specimens ever found, for $31.8 million, trouncing the top-end presale estimate of $8 million. And two years after the Shen auction, financier Ken Griffin spent $44.6 million on a stegosaurus (“a vegetarian,” O’Dowd notes). Leonardo DiCaprio, Nicolas Cage and other celebrities have gotten in on the dino game too.
A dinosaur’s value, like a painting’s or sculpture’s, derives from a protean mix of provenance, desire and authenticity—the last one hard to define, let alone prove, and in the case of an auction, up to the buyer to verify. Christie’s marketing blitz for Shen included the claim that it was one of the most “scientifically studied T. rex skeletons to come to auction,” featuring it in a short promotional video in which the camera cinematically races in for tight shots of its menacing talons and gaping jaw as eerie electronic music pulses in the background. Christie’s made clear that the winning bidder would also get renaming rights, a tradition in which T. rexes in circulation are often given human names.
A month before Shen was supposed to arrive at Christie’s in Hong Kong, it was put on display at Singapore’s Victoria Theatre and Victoria Concert Hall, a stately neoclassical building with a grand clock tower. Families, tourists and prospective buyers in chauffeured Bentleys came to see the T. rex in the flesh, so to speak. But Shen never made it to the auction block…
[Pendleton unpacks the full–and fascinating– tale of Shen. She concludes…]
… In recent years the dinosaur market has gotten only more exuberant. Last year at Sotheby’s a juvenile Ceratosaurus—smaller than a T. rex, but just as carnivorous—sold for $30.5 million, five times its high estimate. Some collectors, including Abu Dhabi’s new natural history museum and German biotech investor Christian Angermayer, are funding teams of bone hunters to scour the fossil-rich western US. Todd Graves, the billionaire behind Raising Cane’s Chicken Fingers, emerged as a collector when he lent his triceratops skull to the Louisiana Art & Science Museum.
And on July 14 in New York, Sotheby’s held what was hyped to be the hottest T. rex auction yet. Gus, as the creature is named, was described as 61% complete by bone count and 75% to 80% by bone mass with “an exceptionally preserved skull.” As the bids climbed, the auctioneer tempted potential buyers. “Try a bigger bite,” she said. “It’s a T. Rex after all.” Gus sold for $50.1 million, the highest ever paid for a dinosaur at auction.
Billionaires and their toys: “The Bone Rush,” gift article from @bloomberg.com.
###
As we ponder possession, we might recall that it was on this date in 1983 that a new species of flesh‑eating dinosaur nicknamed “Claws,” later formally named Baryonyx walkeri was announced…
A huge new dinosaur skeleton has been unveiled to the media at the Natural History Museum in London.
Plumber and amateur fossil hunter Bill Walker, 55, found a foot-long claw belonging to the flesh-eating beast at a clay pit in Surrey in January.
When he found the rock containing the talon he tapped it and the whole thing cracked.
Palaeontologists reconstructed it and dated the remains at 125 million years old, describing them as the find of the century…
… Nicknamed Claws, the dinosaur would have been slightly smaller than the Tyrannosaurus Rex – with teeth like steak knives – and was probably a sub-species of the Megalosaurus.
– source

“What dreadful hot weather we have! It keeps one in a continual state of inelegance.”*…

Climatologist Zeke Hausfather on what’s turning out to be a scorching summer…
I’m generally pretty measured in how I discuss climate data. There has been only one time in recent years when I was truly shocked: when global temperatures came in for September 2023 at a full 0.5C warmer than any prior September on record. Once until today, that is. With the July runs now in from 667 ensemble members across 14 different seasonal forecast models, it looks like this year’s El Niño is not only very likely to be the strongest event since reliable records began – it may end up the strongest by a truly mind-blowing margin.
The multi-model median for the event’s peak (measured as detrended sea surface temperature anomalies in the Niño 3.4 region of the tropical Pacific) currently stands at 3.6C, roughly 0.8C hotter than the prior record of 2.75C set in 2015-16. For context, the gap between the strongest and the fifth strongest El Niño of the past 150 years is only about 0.5C. The models are forecasting something outside the envelope of anything we have ever observed [as the chart at the top illustrates].
A few things stand out in this figure. First, no event in a century and a half of observations has ever pushed meaningfully past 2.75C. The legendary 1877-78 event comes closest, in a statistical dead heat with 2015-16 (2.73C vs 2.75C, well within the uncertainty of 19th-century ship data). Second, the middle 80% of this year’s forecast ensemble sits entirely at or above that all-time record: even the low end of the plume (2.8C) grazes it. Around 91% of ensemble members exceed the 2015-16 record at their peak…
… What is remarkable here is not just the level but the trajectory. The 2026 event is developing faster than 1997-98, the previous gold standard for explosive El Niño onsets. And unlike 2015 which started its year already warm from a precursor event, this one launched from genuinely La Niña-ish conditions in January…
Read on the for the chilling-but-in-the-wrong-way details.
A ~90% chance of a record-setting event: “The Strongest El Niño Ever,” from @zekehausfather.com.
More detail– and opportunity to track the heat– at Zeke’s Climate Dashboard. And for related info, see also Climate.us— the volunteer-fielded “successor” to the now-suppressed Climate.gov.
* Jane Austen, in a 1796 letter to her elder sister, Casandra
###
As we sweat it, we might send scorching birthday greetings to the sublime Martha Reeves; she was born on this date in 1941. A singer, she is best known for her work in Martha and the Vandellas, which scored several major Hot 100 hits, including “Nowhere to Run,” “Jimmy Mack,” “Dancing in the Street,” and of course, “Heat Wave.” In 1995, the group was inducted into the Rock and Roll Hall of Fame; in 2023, Reeves was included on Rolling Stone‘s list of the 200 Greatest Singers of All Time.
“A mouse never entrusts his life to only one hole”*…

… Well, our earth is riddled with them. And as our old friend Randall Munroe at xkcd reminds us, some of them are very deep…
“Holes”
Via Jason Kottke, who reminds us that “Explain xkcd has more info on each of the various holes, including the truly bonkers Cave of Crystals in Mexico” (and explanatory background on other xkcd posts as well…)
* Plautus
###
As we spelunk, we might recall that it was on this date in 1962 that the U.S. military detonated Little Feller I, a tactical nuclear weapon at the Nevada Test Site as part of Operation Sunbeam. It was the last near-ground atmospheric nuclear detonation conducted by the United States. The high-altitude Fishbowl tests concluded in November of1962 with a detonation at around 69,000 feet altitude. Thereafter, in accordance with the 1963 Partial Test Ban Treaty, tests were conducted underground… more holes.
“Invention, my dear friends, is 93% perspiration, 6% electricity, 4% evaporation, and 2% butterscotch ripple”*…
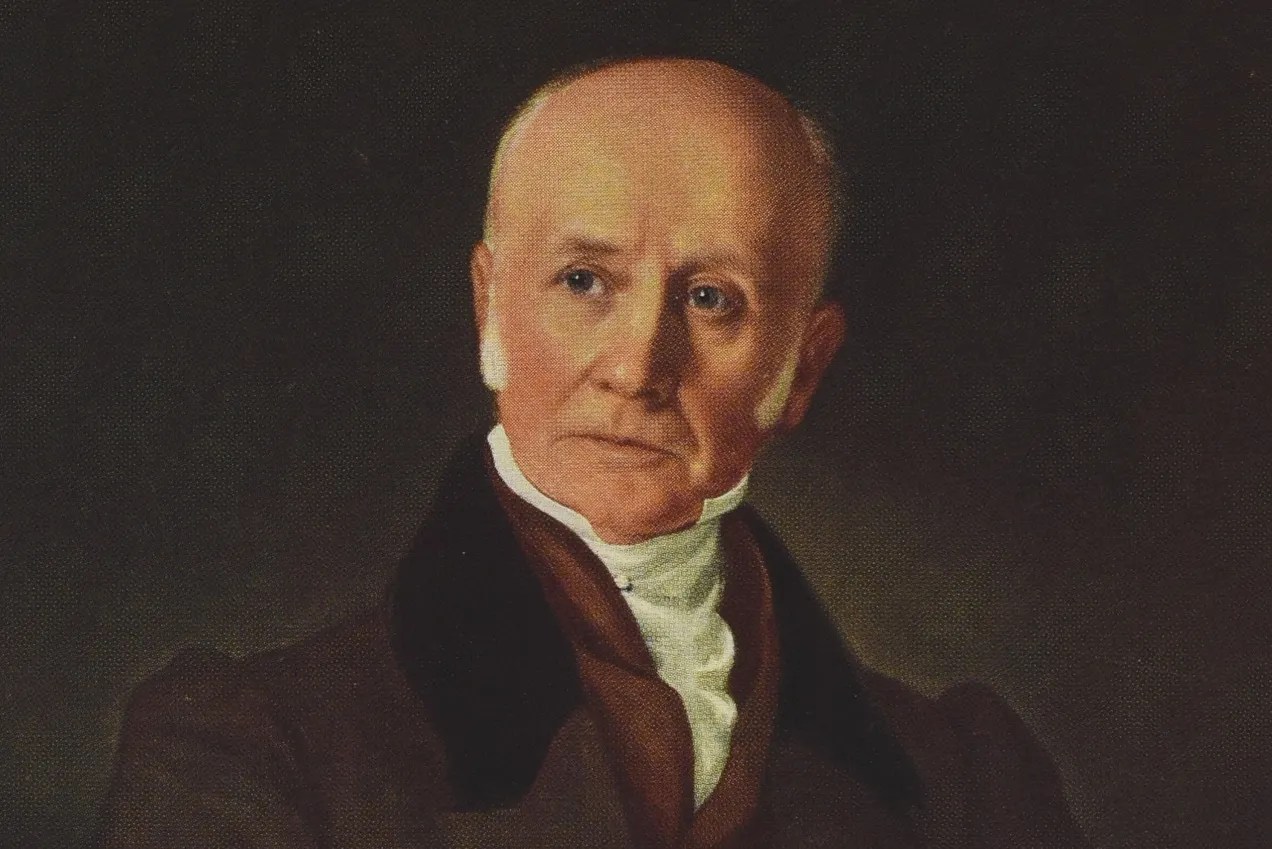
Jason Toon on a man whose applied creativity birthed not one, but two major industries…
Global canned food sales are now more than $210 billion annually. The average American eats about 200 pounds of canned food every year. Meanwhile the worldwide paper industry has seen steep falls in the production of newsprint, printing paper, and writing paper since 2010, but the rise in paper and cardboard packaging has more than made up for it. The paper industry is bigger than ever, with revenue of $485 billion in 2025.
For better or worse, our world would simply not look the same today without these two industries. And one person was the key figure in starting both of them. Bryan Donkin can legitimately claim to be the “father” of the canned-food industry and the paper industry as we know them. So who was he, besides one of the very few guys named Bryan in the 18th century?
Born in northeastern England in 1768, Bryan Donkin went into the same business as his father: real estate. But it didn’t speak to him. So in 1792, at the rather ripe age of 24, he became an apprentice to John Hall at Dartford Iron Works to pursue his true calling as an engineer.
At the time, all paper was made by hand, more or less the same way it had been done since the Middle Ages. Cotton and linen rags were soaked in water and beaten into a pulp. A shallow, rectangular mold with a screen bottom would be dipped into the liquid slurry and shaken. A thin layer of the macerated fibers would settle on the screen; when dry, you’d have yourself a single sheet of paper.
Donkin started his post-apprenticeship career making these molds. But around 1801, he got connected to the Fourdrinier brothers, who produced stationery in London. They’d made a deal with a French inventor, Louis-Nicolas Robert, to bring a new paper-making machine to Britain. At the time, between the post-revolutionary turmoil in France and England’s more advanced industrial base, the latter seemed to hold more lucrative prospects for the new invention.
Unlike the laborious single-sheet, mold-based method, this new “Fourdrinier machine” used a cylinder to continuously produce rolls of paper. A mechanism called the “shake” agitated the conveyor belt at a high speed, to spread the wet pulp fibers in an even layer. Unfortunately, this rapid movement put a lot of strain on the mostly wooden machine. One of Donkin’s improvements was to use metal parts instead, for improved stability and precision.
Another refinement of his was adjusting the rollers that squeezed the water out of the paper, to maximize contact between them and the paper, to dry the paper more quickly and thoroughly. This and other improvements turned the Fourdrinier machine from an interesting prototype to a viable technical advancement.
It quickly became the industry standard, and remains so over 200 years later. The publishing boom of the late 19th and early 20th century wouldn’t have been possible without it. Those big machines you see today producing rolls of paper are most likely Fourdrinier machines. Donkin also made some key advancements in printing technology, so the Pulitzers and Murdochs of the world owe him double gratitude.
His fortune secured, now the head of a company bearing his name that still exists (these days they make gas valves), Donkin’s restless mind turned to another puzzle: the preservation of food. Like too many technological quests, this one was spurred by military needs. Best frenemies England and France were both spreading their empires around the planet, frequently clashing, and looking for ways to keep their troops fed. In such wide-ranging conflicts as the Seven Years’ War (1756-1763), far more sailors died of malnutrition than in combat.
It seems yet another French inventor had visions of pounds sterling dancing in his eyes. Philippe de Girard had come up with a method of preserving food by putting in inside a sealed tin container, then boiling the container in water to sterilize it. Or maybe he swiped the method from another French inventor, Nicolas Appert [see here]. Or maybe they were in cahoots. What we do know is that in 1810, de Girard went to London and engaged a merchant named Peter Durand to be his frontman for getting a British patent, which de Girard would not have been eligible for since Britain and France were at war.
Durand was duly awarded the patent in his name. Ever since, he’s been often called the inventor of the tin can, despite having nothing to do with inventing it, and doing nothing with it except selling the patent for £1,000 in 1812. The buyer? Bryan Donkin’s old apprenticeship master, John Hall.
Now on equal terms as budding titans of industry, Hall put up the money and Donkin provided the brains along with a third partner, John Gamble, to bring tin canning to an industrial scale. Again, it took a couple of years, but Donkin and Gamble steadily refined the process. One of their major innovations was to use iron coated in a thin layer of tin, combining the strength of the former with the non-reactive properties of the latter for an imperturbable can that could survive the longest, roughest ocean voyages.
For the second time, a French invention plus Donkin’s enhancements equaled le jackpot. After getting the likes of Queen Charlotte and the Duke of Wellington hooked with some free samples of canned beef, the firm of Donkin, Hall and Gamble received an order for 156 pounds of canned food from the Admiralty in 1813. That grew to 2,939 pounds the following year, increasing annually to 9,000 pounds by 1821.
Having bested the canning challenge, Donkin again wandered off in search of other worlds to conquer: helping Charles Babbage with the “difference engine” that would eventually become the computer, consulting on bridge and canal projects, inventing the first metal pen and a screw-cutting machine, being a founding member of both the Institution of Civil Engineers and the Royal Astronomical Society.
He died in 1855, an esteemed eminence in Victorian scientific and engineering circles. Today Bryan Donkin’s impact is out of all proportion to his memory. On a visit to his grave in London, the BBC found, [there was] no mention of his achievements. Cemetery staff didn’t know who he was.
I can sense the question from some quarters of the audience: are Bryan Donkin’s achievements worth celebrating? Not only did canned food help enable imperial conquest and war, it also led eventually to the mass industrialization of food production, with its attendant crises of public health and monocultural farming, and our psychological distance from our food supply. And one look at any municipal dump will show you how much paper and cardboard waste still goes into landfill, even in a supposedly “paperless world”.
Those points are well taken. But it’s easier to dismiss these advancements when you live in a world that’s always known them. Over the last century or two, large-scale paper production enabled the rise of mass literacy, from only 10% of the world’s population being literate in 1820 to 90% today.
And it’s not just British seamen who eat better because of canned food. A 2011-2013 National Institutes of Health study found that people who eat six or more canned items a week “consume more nutrient-dense food groups such as fruits, vegetables, dairy products, and protein-rich foods, and also have higher intakes of 17 essential nutrients” including potassium, calcium, and fiber. Canned food has helped overcome the tyrannies of distance and time to get more nutrition to more people.
From the perspective of people in 1810, both food canning and mass paper production were immense steps forward. We can’t lay our subsequent inability to maintain some equilibrium at their feet. It’s true that Bryan Donkin didn’t invent the machines he perfected. Both industries probably would have happened, in some form, eventually, without him. But in being the first to perfect them for large-scale use, and granting all the downsides they’ve brought along with them, he hastened the coming of a less hungry, more educated world. Not bad for a guy named Bryan…
How one genius fathered both the canning and paper industries: “The Lives of Bryan,” from @jasontoon.bsky.social.
* Willy Wonka (in Roald Dahl’s Charlie and the Chocolate Factory)
###
As we devise, we might send carefully-calculated birthday greetings to Dan Bricklin; he was born on this date in 1951. An engineer, he was the co-creator, with Bob Frankston, of VisiCalc, the first spreadsheet program. Known as “the father of the Spreadsheet,” he was awarded the Grace Murray Hopper Award in 1981 for VisiCalc and was one of six people spotlighted when “the Computer” was named “Machine of the Year” by Time magazine in 1982.
Neither Bricklin nor Frankston reaped huge financial profits from their spreadsheet program, though it sold over a half-million copies by 1983. At the time, copyright protection was not generally sought for software; their company was subsequently acquired by Lotus 1-2-3, which became the new spreadsheet standard (until, of course, Excel).

“When you mix science and politics, you get politics:*…

Tina Hesman Saey on a looming threat to the U.S…
Soviet scientists in the 1930s knew what could happen if they bucked the party line: denunciation, firing and banishment from the scientific establishment, even imprisonment and death. Political reprisals against those who opposed the views of dictator Joseph Stalin and his followers — and the dubious science they endorsed — led to the starvation of millions, as well as to decades of lost progress in fields from agriculture to molecular biology.
Now, scientists are warning that history could repeat itself — but in the United States.
A new proposal from the U.S. Office of Management and Budget would put political appointees in charge of funding decisions traditionally overseen by scientists. In recent years, the federal government has funded about 40 percent of basic science research in the United States.
The OMB’s more than 400-page proposed rule change would let political appointees decide how to hand out federal research funds and who can get them. It would cut funding for collaboration with scientists in other countries and restrict scientists’ ability to communicate their findings. What’s more, it could prevent research on matters that President Donald Trump’s administration has deemed “not in the national interest” — such as studies on health disparities, mRNA-based vaccines and research that doesn’t recognize biological sex as a strict binary.
The new rules would also give OMB the power to rescind previously approved research funds. The proposal “poses a sweeping threat to federal grantmaking and the responsible stewardship of American taxpayer dollars,” the science advocacy group Stand Up for Science Foundation said in a report. In addition, it would impact nonscientific grants supporting services for mental health, housing, education, veterans and Tribal nations, affecting the health and well-being of millions.
So far, OMB has received more than 98,000 comments on the proposal. The public comment period closes July 13. It then will be up to OMB to decide whether to keep the rule as is, revise it or scrap it.
These far-reaching measures are already drawing parallels to dark moments in scientific history. Some researchers say the recent mass firings, policy changes and grant cancellations at federal research institutions, including the U.S. National Institutes of Health and Centers for Disease Control and Prevention, closely mirror what happened in the U.S.S.R. under Stalin. “A similar threat now hangs over U.S. science,” the editorial board of The New England Journal of Medicine wrote in June.
Its editorial invoked the example of Trofim Lysenko [see here], an agronomist and astute political operator who rose to power in the 1930s Soviet Union under Stalin.
Until the 1930s, “the Soviet Union was a real powerhouse in the field of genetics,” says Lee Dugatkin, an evolutionary biologist and historian of science at the University of Louisville in Kentucky.
Then, Lysenko came along. “This guy was your sort of classic charlatan,” Dugatkin says. “He had the equivalent of a mail order degree in agriculture, but he was quite good with the press, and he started to basically spread this idea out there that he was capable of dramatically increasing crop yield, particularly wheat.”
Lysenko’s supposed innovation was a process called vernalization and amounted to soaking seeds in freezing water. The resulting plants — and all their offspring — should be resistant to the U.S.S.R.’s famously cold winters, Lysenko reasoned.
His reasoning was based on a disproven idea in evolutionary biology called Lamarckian inheritance. French biologist Jean-Baptiste Lamarck and his followers thought that things an organism experiences in its lifetime can be handed down to the next generation. The classic example is a giraffe that has to stretch to reach leaves producing offspring with long necks.
This idea ran counter to Mendelian genetics, which holds that genes — not environmental influences — control traits and are passed to offspring. Mendelian geneticists thought it would take five years to breed more cold-tolerant crops. Lysenko said he could do it in two to three years.
Stalin didn’t have time to wait. He was trying to get collective farms going and needed to increase crop yields to feed more than 150 million people. Large parts of the country had already suffered from famine in 1932 and 1933 and about 6 million people died. Some resorted to cannibalism.
Stalin embraced Lysenko’s quick-fix approach. That decision, says Michael Gordin, a historian of science at Princeton University, was “something that the majority of people at the time, and everyone since, considers the wrong side of the dispute.”
Lysenko was put in charge of a prestigious genetics institute and forced his scientifically unsound farming practices on the collective farms. His methods were disastrous.
Soaking seeds in freezing water hampered germination, leading to crop losses. Millions starved. Meanwhile, Mendelian genetics was branded a “whore of capitalism,” and geneticists were forced to renounce their views or lose their jobs. Many were jailed, and almost a dozen were executed or died in prison.
The Soviet Union lost its scientific leadership role and sat on the sidelines for important scientific discoveries of the 1950s and beyond. One, Gordin says, was the development of “massively” productive hybrid corn. The country also missed out on the discovery of DNA and the advent of molecular biology, putting Soviet genetics decades behind the rest of the world.
Soviet genetics did not recover from Lysenko’s influence until after the break-up of the Soviet Union in the late 1980s and early 1990s, Gordin says. “I think you’d be hard pressed to find anybody who thinks that … Russia is today, or Ukraine, or any post-Soviet successor state, is a leading molecular biology country.”…
The Soviets did it, and it didn’t end well: “Here’s what happens when you put politicians in charge of science,” from @thsaey.bsky.social in @sciencenews.bsky.social.
See also: Idiocracy
###
As we remember the past so as not to repeat it, we might recall that it was on this date in 1834 that the Spanish Inquisition (finally) ended. Authorized by Pope Sixtus IV in 1478, the Inqusition was initially led by inquisitors (Miguel de Morillo and Juan de San Martín) who were appointed by the future Catholic monarchs, King Ferdinand II of Aragon and Queen Isabella I of Castile. It was originally (ostensibly) intended primarily to identify heretics; its aim, to maintain Christian orthodoxy. But it became an effective instrument of state power by replacing the Medieval Inquisition, which was under Papal control.
Over its course, the Inquisition prosecuted an estimated 150,000 people for various offences. An estimated 3,000–5,000 were turned over to the state for execution, particularly in the initial 50 years, mostly by burning at the stake. Other punishments included penance and public flogging, exile, enslavement on galleys, and prison terms ranging from several years to life. In many of these punishments an important motive was the confiscation of all the victims’ property.
As Monty Python observed, “nobody expects the Spanish Inquisition.” And nobody expected it to last 356 years.

You must be logged in to post a comment.