Posts Tagged ‘communications’
“The economic system is, in effect, a mere function of social organization”*…

The AI race is, of course, afoot. But while most headlines focus on the new capabilities and benchmarks achieved by competing developers, Jeremy Shapiro reminds us that the winners in this race won’t necessarily be the most objectively capable, but rather the players who most effectively integrate the technology into their organizations, economies, and societies…
Artificial intelligence has rapidly become a central arena of geopolitical competition. The United States government frames AI as a strategic asset on par with energy or defense and seeks to press its apparent lead in developing the technology. The European Union lags in platform power but seeks influence over AI through regulation, labor protections, and rule-setting. China is racing to catch up and to deploy AI at scale, combining heavy state investment with administrative control and surveillance.
Each of these rivals fears falling behind. Losing the AI race is widely understood to mean slower growth, military disadvantage, technological dependence, and diminished global influence. As a result, governments are pouring money into chips, data centers, and national AI champions, while tightening export controls and treating compute capacity as a strategic resource. But this familiar race narrative obscures a deeper danger. AI is not just another general-purpose technology. It is a force capable of reshaping the very meaning of work, income, and social status. The states that lose control of these social effects may find that technological leadership offers little geopolitical advantage.
History suggests that societies unable to absorb disruptive economic change become politically volatile, strategically erratic, and ultimately weaker competitors. The central question, then, is not only who builds the most powerful AI systems, but who can integrate them into society without triggering a societal backlash or an institutional breakdown.
Karl Polanyi’s The Great Transformation, published in 1944, explains why the capacity to “socially embed” new market forces determines national strength. By “embeddedness,” Polanyi meant that markets have historically been subordinate to social and political institutions, rather than governing them. The nineteenthcentury idea of what he called a “self-regulating market” was historically novel precisely because it sought to “disembed” the economy from society and organize social life around price and competition rather than social obligation. As Polanyi put it in his most succinct formulation, “instead of economy being embedded in social relations, social relations are embedded in the economic system.”
Writing in the shadow of the Great Depression, Polanyi argued that the attempt in the nineteenth century to create a self-regulating market society that treated labor, land, and money as commodities generated social dislocation so severe that it provoked authoritarian backlash and geopolitical collapse. Stable orders, he insisted, required markets to be re-embedded in social and political institutions. Where they were not, societies sought protection by other means, which often translated into support for fascist or communist regimes that promised to tame the market. Today, it often means electing populist leaders who promise to break the entire existing order, both domestic and international.
Polanyi insisted that the idea of a “self-adjusting market implied a stark utopia” because such a system could not exist “for any length of time without annihilating the human and natural substance of society.” The interwar gold standard, for example, disciplined states in the name of efficiency, but it did so by transmitting economic shocks directly into social life. When democratic governments proved unable to shield their populations, they either abandoned the liberal economic order or turned authoritarian (or both)…
[Shapiro considers the history of the 20th century, in particular the rise of Nazi Gernmany, sketches the state of play in the AI arena, considers the challenge of embedding the changes that AI will bring in The U.S., Europe, and China, then teases out the ways in which the “industrial revolution” is different from it predecessors (in particular, the mobility of capital, the services (as opposed to manufacturing)-heavy character of employment today, and the accelerating pace of tech deelopment. He concludes…]
… Geopolitical competition in the AI age will not take place solely in clean rooms or data centers. It will also involve the less visible realm of social institutions: labor markets, communities, social protections, and political legitimacy. Polanyi teaches us that markets are powerful only when societies can bear them. When they cannot, markets provoke their own undoing and often in rather spectacular fashion.
The West’s success in the Cold War owed much to its ability to reconcile capitalism with social protection. If the AI age is another “great transformation,” the same lesson applies. Chips matter. Data matters. But the ultimate source of power may be the capacity to re-embed technological change in society without sacrificing cohesion.
That is not a liberal-progressive distraction from geopolitical competition. It is its hidden core.
“The Next Great Transformation,” from @jyshapiro.bsky.social and @open-society.bsky.social.
For a complementary perspective (with special focus on the interaction between labor and the supply side of the economy) pair with: “Brave New World- a third industrial divide?” from @thunen.bsky.social in @phenomenalworld.bsky.social.
And see also: “AI and the Futures of Work,” from Johannes Kleske (@jkleske.bsky.social). A response to dramatic predictions of AI’s impact– most recently, Matt Shumer‘s viral “Something Big Is Happening“: it’s a possible future, Kleske suggests. but only one possibe future– and one that, while plausible, isn’t likely (at least outside the rarified atmsphere of coding, in which Shumer operates). In a way that echoes Shapiro’s piece above, Kleske suggests that individuals need to better understand the technology in order to retain/regain some agency, and societies need the same kind of rekindled resistance to act clearly and with purpose in re-embedding AI, and markets, in society. Not the other way around… Resonant with the thinking of Tim O’Reilly and Mike Loukides featured here before: “The best way to predict the future is to invent it“; and with Ted Chiang‘s “ChatGPT Is a Blurry JPEG of the Web” and “Will A.I. Become the New McKinsey?” And then there’s the ever-illuminating Rusty Foster (riffing on Gideon Lewis-Kraus‘ recent New Yorker piece): “A. I. Isn’t People.”
For a look at a high-value, trust-based use case for AI that seems to avoid the objections to AGI (and speak to Shapiro’s points), see “The Middle Game: Routers at the Edge,” from Byrne Hobart.
But back to AGI… as Nicholas Carr observes, we might understand Bosrtrom’s “paperclip maximizer” “not as a thought experiment but as a fable. It’s not really about AIs making paperclips. It’s about people making AIs. Look around. Are we not madly harvesting the world’s resources in a monomaniacal attempt to optimize artificial intelligence? Are we not trapped in an “AI maximizer” scenario?”
###
As we digest development, we might recall that it was on this date in 1962 that an early precondition for the revolution underway was first achieved: telephone and television signals were first relayed in space via the communications satellite Echo 1– basically a big metallic balloon that simply bounced radio signals off its surface. Simple, but effective.
Forty thousand pounds (18,144 kg) of air was required to inflate the sphere on the ground; so it was inflated in space. While in orbit it only required several pounds of gas to keep it inflated.
Fun fact: the Echo 1 was built for NASA by Gilmore Schjeldahl, a Minnesota inventor probably better remembered as the creator of the plastic-lined airsickness bag.

“They will read many things without instruction and will therefore seem to know many things, when they are for the most part ignorant and hard to get along with, since they are not wise, but only appear wise.”*…

Socrates was worried about the impact of a new technology– writing– on effetive intelligence of its users. Similar concerns have surfaced with the rise of other new communications technologies: moveable-type printing, photography, radio, television, and the internet. As Erik Hoel reminds us, AI is next on that list…
Unfortunately, there’s a growing subfield of psychology research pointing to cognitive atrophy from too much AI usage.
Evidence includes a new paper published by a cohort of researchers at Microsoft (not exactly a group predisposed to finding evidence for brain drain). Yet they do indeed see the effect in the critical thinking of knowledge workers who make heavy use of AI in their workflows.
To measure this, the researchers at Microsoft needed a definition of critical thinking. They used one of the oldest and most storied in the academic literature: that of mid-20th century education researcher Benjamin Bloom (the very same Benjamin Bloom who popularized tutoring as the most effective method of education).
Bloom’s taxonomy of critical thinking makes a great deal of sense. Below, you can see how what we’d call “the creative act” occupies the top two entries of the pyramid of critical thinking, wherein creativity is a combination of the synthesis of new ideas and then evaluative refinement over them.

To see where AI usage shows up in Bloom’s hierarchy, researchers surveyed a group of 319 knowledge workers who had incorporated AI into their workflow. What makes this survey noteworthy is how in-depth it is. They didn’t just ask for opinions; instead they compiled ~1,000 real-world examples of tasks the workers complete with AI assistance, and then surveyed them specifically about those in all sorts of ways, including qualitative and quantitative judgements.
In general, they found that AI decreased the amount of effort spent on critical thinking when performing a task…
… While the researchers themselves don’t make the connection, their data fits the intuitive idea that positive use of AI tools is when they shift cognitive tasks upward in terms of their level of abstraction.
We can view this through the lens of one of the most cited papers in all psychology, “The Magical Number Seven, Plus or Minus Two,” which introduced the eponymous Miller’s law: that working memory in humans caps out at 7 (plus or minus 2) different things. But the critical insight from the author, psychologist George Miller, is that experts don’t really have greater working memory. They’re actually still stuck at ~7 things. Instead, their advantage is how they mentally “chunk” the problem up at a higher-level of abstraction than non-experts, so their 7 things are worth a lot more when in mental motion. The classic example is that poor Chess players think in terms of individual pieces and individual moves, but great Chess players think in terms of patterns of pieces, which are the “chunks” shifted around when playing.
I think the positive aspect for AI augmentation of human workflows can be framed in light of Miller’s law: AI usage is cognitively healthy when it allows humans to mentally “chunk” tasks at a higher level of abstraction.
But if that’s the clear upside, the downside is just as clear. As the Microsoft researchers themselves say…
While GenAI can improve worker efficiency, it can inhibit critical engagement with work and can potentially lead to long-term over-reliance on the tool and diminished skill for independent problem-solving.
This negative effect scaled with the worker’s trust in AI: the more they blindly trusted AI results, the more outsourcing of critical thinking they suffered. That’s bad news, especially if these systems ever do permanently solve their hallucination problem, since many users will be shifted into the “high trust” category by dint of sheer competence.
The study isn’t alone. There’s increasing evidence for the detrimental effects of cognitive offloading, like that creativity gets hindered when there’s reliance on AI usage, and that over-reliance on AI is greatest when outputs are difficult to evaluate. Humans are even willing to offload to AI the decision to kill, at least in mock studies on simulated drone warfare decisions. And again, it was participants less confident in their own judgments, and more trusting of the AI when it disagreed with them, who got brain drained the most…
… Admittedly, there’s not yet high-quality causal evidence for lasting brain drain from AI use. But so it goes with subjects of this nature. What makes these debates difficult is that we want mono-causal universality in order to make ironclad claims about technology’s effect on society. It would be a lot easier to point to the downsides of internet and social media use if it simply made everyone’s attention spans equally shorter and everyone’s mental health equally worse, but that obviously isn’t the case. E.g., long-form content, like blogs, have blossomed on the internet.
But it’s also foolish to therefore dismiss the concern about shorter attention spans, because people will literally describe their own attention spans as shortening! They’ll write personal essays about it, or ask for help with dealing with it, or casually describe it as a generational issue, and the effect continues to be found in academic research.
With that caveat in mind, there’s now enough suggestive evidence from self-reports and workflow analysis to take “brAIn drAIn” seriously as a societal downside to the technology (adding to the list of other issues like AI slop and existential risk).
Similarly to how people use the internet in healthy and unhealthy ways, I think we should expect differential effects. For skilled knowledge workers with strong confidence in their own abilities, AI will be a tool to chunk up cognitively-demanding tasks at a higher level of abstraction in accordance with Miller’s law. For others… it’ll be a crutch.
So then what’s the take-away?
For one, I think we should be cautious about AI exposure in children. E.g., there is evidence from another paper in the brain-drain research subfield wherein it was younger AI users who showed the most dependency, and the younger cohort also didn’t match the critical thinking skills of older, more skeptical, AI users. As a young user put it:
It’s great to have all this information at my fingertips, but I sometimes worry that I’m not really learning or retaining anything. I rely so much on AI that I don’t think I’d know how to solve certain problems without it.
What a lovely new concern for parents we’ve invented!
Already nowadays, parents have to weather internal debates and worries about exposure to short-form video content platforms like TikTok. Of course, certain parents hand their kids an iPad essentially the day they’re born. But culturally this raises eyebrows, the same way handing out junk food at every meal does. Parents are a judgy bunch, which is often for the good, as it makes them cautious instead of waiting for some finalized scientific answer. While there’s still ongoing academic debate about the psychological effects of early smartphone usage, in general the results are visceral and obvious enough in real life for parents to make conservative decisions about prohibition, agonizing over when to introduce phones, the kind of phone, how to not overexpose their child to social media or addictive video games, etc.
Similarly, parents (and schools) will need to be careful about whether kids (and students) rely too much on AI early on. I personally am not worried about a graduate student using ChatGPT to code up eye-catching figures to show off their gathered data. There, the graduate student is using the technology appropriately to create a scientific paper via manipulating more abstract mental chunks (trust me, you don’t get into science to plod through the annoying intricacies of Matplotlib). I am, however, very worried about a 7th grader using AI to do their homework, and then, furthermore, coming to it with questions they should be thinking through themselves, because inevitably those questions are going to be about more and more minor things. People already worry enough about a generation of “iPad kids.” I don’t think we want to worry about a generation of brain-drained “meat puppets” next.
For individuals themselves, the main actionable thing to do about brain drain is to internalize a rule-of-thumb the academic literature already shows: Skepticism of AI capabilities—independent of if that skepticism is warranted or not!—makes for healthier AI usage.
In other words, pro-human bias and AI distrust are cognitively beneficial.
It’s said that first we shape our tools, then they shape us. Well, meet the new boss, same as the old boss… Just as, both as individuals and societies, we’ve had to learn our way into effective use of new technologes before, so we will with AI.
The enhancement and atrophy of human cognition go hand in hand: “brAIn drAIn,” from @erikphoel.
Pair with a broad and thoughtful view from Robin Sloan: “Is It OK?“
* “For this invention will produce forgetfulness in the minds of those who learn to use it, because they will not practice their memory. Their trust in writing, produced by external characters which are no part of themselves, will discourage the use of their own memory within them. You have invented an elixir not of memory, but of reminding; and you offer your pupils the appearance of wisdom, not true wisdom, for they will read many things without instruction and will therefore seem to know many things, when they are for the most part ignorant and hard to get along with, since they are not wise, but only appear wise.” – Socrates, in Plato’s dialogue Phaedrus 14, 274c-275b
###
As we think about thinking, we might send carefully-considered birthday greetings to Alfred North Whitehead; he was born on this date in 1861. Whitehead began his career as a mathematician and logician, perhaps most famously co-authoring (with his former student, Bertrand Russell), the three-volume Principia Mathematica (1910–13), one of the twentieth century’s most important works in mathematical logic.
But in the late teens and early 20s, Whitehead shifted his focus to philosophy, the central result of which was a new field called process philosophy, which has found application in a wide variety of disciplines (e.g., ecology, theology, education, physics, biology, economics, and psychology).
“There is urgency in coming to see the world as a web of interrelated processes of which we are integral parts, so that all of our choices and actions have consequences for the world around us.”

“With new technologies promising endless conveniences also come new vulnerabilities”*…
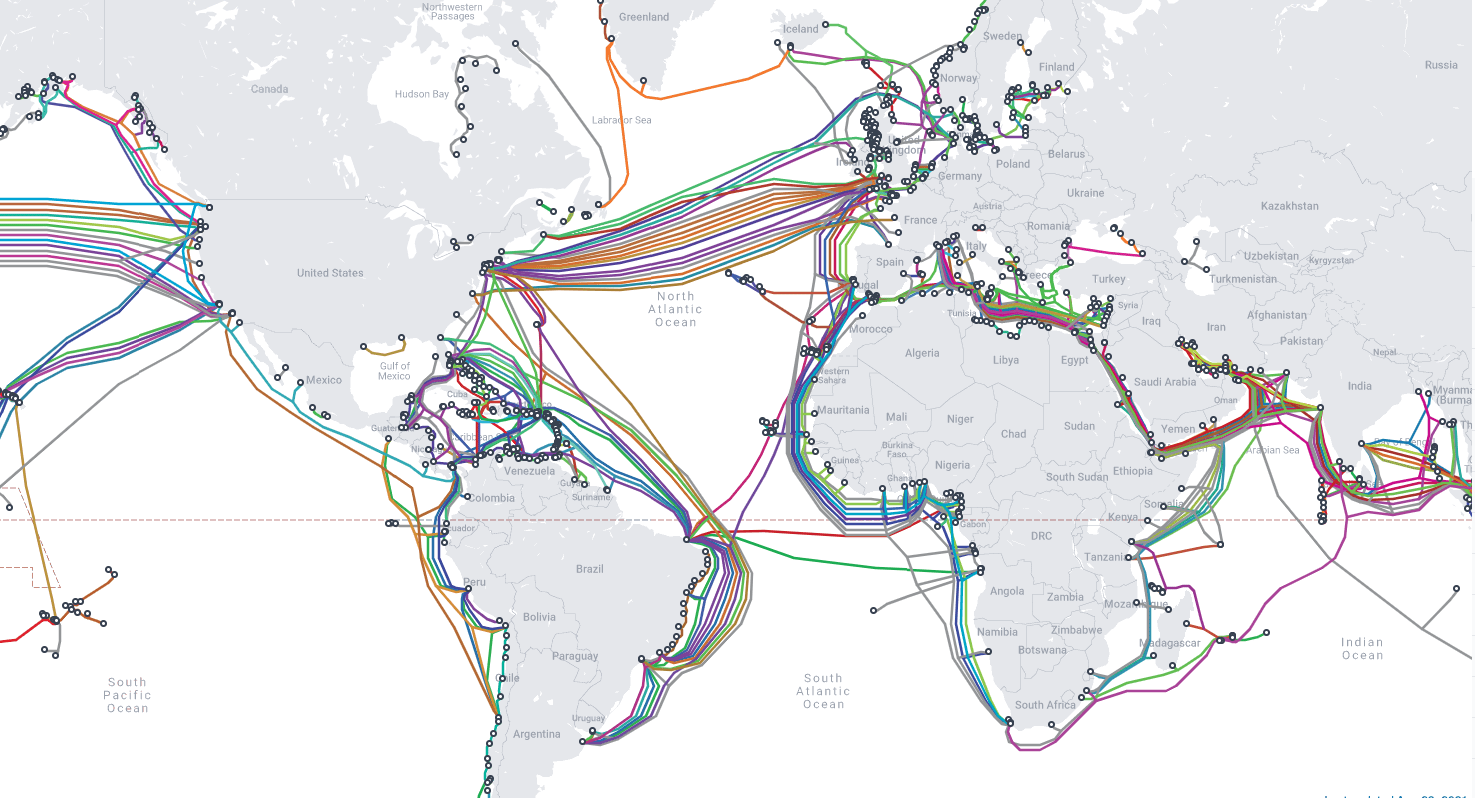
Many of us assume that most global communication is accomplished via satellite; in fact over 95 percent of international data and voice transfers are currently routed through the many fiber optic lines that crisscross the world’s seafloors. Earlier this year, (R)D took a look at the folks who lay, maintain, and repair these crucial cables. As noted there…
If, hypothetically, all these cables were to simultaneously break, modern civilization would cease to function. The financial system would immediately freeze. Currency trading would stop; stock exchanges would close. Banks and governments would be unable to move funds between countries because the Swift and US interbank systems both rely on submarine cables to settle over $10 trillion in transactions each day. In large swaths of the world, people would discover their credit cards no longer worked and ATMs would dispense no cash. As US Federal Reserve staff director Steve Malphrus said at a 2009 cable security conference, “When communications networks go down, the financial services sector does not grind to a halt. It snaps to a halt.”
Corporations would lose the ability to coordinate overseas manufacturing and logistics. Seemingly local institutions would be paralyzed as outsourced accounting, personnel, and customer service departments went dark. Governments, which rely on the same cables as everyone else for the vast majority of their communications, would be largely cut off from their overseas outposts and each other. Satellites would not be able to pick up even half a percent of the traffic. Contemplating the prospect of a mass cable cut to the UK, then-MP Rishi Sunak concluded, “Short of nuclear or biological warfare, it is difficult to think of a threat that could be more justifiably described as existential.”
Now, from TeleGeography, the interactive Submarine Cable Map, a free and regularly updated resource that allows one to locate any of the over 600 cable systems connecting the world. [Submarine Cable FAQ; even more here].
It’s fascinating to browse. Note, for example, the confluence of cables at the Northern Marianas and Guam…

Charting the web that connects the world: “Submarine Cable Map” from @TeleGeography.
Apposite: an argument that networks of connectivity are the battleground of the future: “From Mass to Distributed Weapons of Destruction.”
* Clara Shih
###
As we contemplate connectivity, we might note that John Mullaly was born on this date in 1835. Mullaly immigrated from Belfast to New York City, where he became a journalist. In 1854, he followed a story to Newfoundland, where he covered the laying of the first Transatlantic Telegraph Cable, in a series of articles, then in a book. Indeed, Mullaly became a booster of undersea cables, lecturing on them.
At the outbreak of the Civil War, Mullaly fell afoul of federal authorities by advocating against the draft. After the war, he left journalism for politics, joining the famously-corrupt Tweed Ring and Tammany Hall, where he became involved in the annexation of property in the Bronx (which had been unincorporated parts of Westchester County). Interestingly, Mullaly worked to create public parks in the Bronx, and founded the New York Park Association in 1881. His efforts culminated in the 1884 New Parks Act and the city’s 1888-90 purchase of lands (on many of which Mullaly and his Tammany cronies are believed to have profited) for Van Cortlandt, Claremont, Crotona, Bronx, St. Mary’s, and Pelham Bay Parks and the Mosholu, Pelham, and Crotona Parkways.
Mullaly Park in the south Bronx was named after him. But in 2021, after criticism and protests against Mullaly’s racist rhetoric during the murderous New York City draft riots (which Mullaly helped incite), the NYC Parks Department announced they would remove Mullaly’s name, instead honoring Reverend Wendell T Foster, the first Black elected in the Bronx (who as a long-standing New York City Council Member was a champion of the park and the neighborhood).

“If you are not paying for it, you’re not the customer; you’re the product being sold.”*…

Julia Barton on a question that haunts us still…
After yet another day reading about audio industry layoffs and show cancellations, or listening to podcasts about layoffs and show cancellations, I sometimes wonder, “With all this great audio being given away for free, who did we think was supposed to pay for it all?”
I find some consolation in the fact that that question is more than a century old. In the spring of 1924, Radio Broadcast posed it in a contest called “Who is to Pay for Broadcasting and How?”The monthly trade magazine offered a prize of $500 (more than $9,000 in today’s dollars) for “a workable plan which shall take into account the problems in present radio broadcasting and propose a practical solution.”
The need for such a contest more than 100 years ago is revealing enough, but the reaction of the judges to the prize-winning plan turned out to be even more so — and it says a lot about why business models for audio production and broadcast remain a struggle.
Back in the mid-1920s, radio was just starting to catch on in America. For a couple of decades, the medium had been used mostly for logistics, to help ships communicate with each other and the shore. But after World War I, new technology allowed Americans to send and receive the sounds of music, lectures, and live events over “the ether.”
By all accounts, Americans — whiplashed by war, a flu pandemic, and massive social changes like Prohibition — went crazy to hear what the ether could deliver to the privacy of their homes. They started buying or building their own radio receivers at a pace that shocked observers. In his book This Fascinating Radio Business, Robert Landry recalls curious customers lining up behind velvet ropes to see and place orders for the latest receivers. “The size, cost, gloss and make of one’s radio was, with the family car and the family icebox, an index of social swank.”
Many stations at the time were run by department stores that wanted to demonstrate the miracle of the expensive radio sets they sold. One of the first broadcast radio stations in the country, WOR sat in the furniture department at Bamberger’s in Newark, and its first announcers were also the employees selling furniture. But as the consumer market started to be saturated, those early stations were either bleeding money or shutting down entirely. The equipment needed constant updating, the workers expected salaries, and the performers who’d once been persuaded to fill airtime “for exposure” now demanded payment.
To make things more complicated, the government required so-called “clear channel” stations (high-powered, with signals that reached far and wide) to be on the air live for 18 hours a day, forbidding the use of “mechanically reproduced” music (as in, phonograph records) to fill the time. All this made broadcasting a very expensive proposition by 1924.
I first read about the “Who Is To Pay” contest in the 1994 book Selling Radio by Susan Smulyan, who starts off noting that from the beginning, “no one knew how to make money from broadcasting.” What about advertising, the solution that seems most obvious in hindsight? The man in charge of regulating radio, then-Secretary of Commerce Herbert Hoover, hated the idea.
“I don’t think there is anything the people would take more offense at than the attempt to sell goods over radio advertising,” Hoover declared, as part of a full-page spread in The New York Times on May 18, 1924, the same month that Radio Broadcast first announced its contest.
The Secretary had been speaking out against advertising for a few years by this point. Indirect advertising (or sponsorship, as it would soon be called) was acceptable in his mind — and via some math that’s hard to figure out, he guessed sponsorship could support about 150 stations nationwide.
Consumers in the 1920s were used to paying for telephone calls and telegrams, and there were other experiments to get listeners to pay for radio. One, dubbed “wired wireless,” licensed special devices to subscribers on Staten Island, who then got programs delivered via their power lines — a proto-version of cable TV that didn’t last long…
… Radio Broadcast received close to a thousand entries to its contest. They proposed everything from a 30-day fundraising drive to the sale of copyrighted radio programming bulletins. The winner, announced in the March 1925 issue, proposed a $2 federal tax on vacuum tubes, at the time the cutting-edge technology for radio reception. The prizewinner, HD Kellogg Jr. of Haverford, Pennsylvania, reasoned that vacuum tubes were the best index of high-quality gear — the better the gear, the more radio a household could consume. Kellogg also argued that only the federal government, which already regulated radio, could collect and administer such a tax. His idea was basically a less regressive version of the licensing fee the British government already levied U.K. households to fund the BBC.
Though the contest’s judges awarded Kellogg’s proposal their prize, they were ambivalent about, if not downright hostile to, his plan. One can only imagine young Kellogg’s feelings as he read the many dismissals of his idea in later issues of Radio Broadcast. “A Government tax would be obnoxious,” wrote Paul Klugh, executive chairman of the National Association of Broadcasters. “I do not believe your prize-winning plan is feasible under conditions as they exist in this country,” wrote Secretary Hoover.
America’s radio brain trust would go on to denounce almost any federal funds for broadcasting, fearing such a model could lead to censorship. Some of that aversion makes historical sense, given that Americans could still vividly remember the ugly and heavy-handed wartime censorship of Wilson-era U.S. postmaster Albert Sidney Burleson. As Adam Hochshild writes in his chilling history American Midnight, Burleson — until he left Washington with his boss Woodrow Wilson in 1921 — used his office to seize socialist and foreign-language publications, and revoke the postal privilege of other publications that reported on the war. So when broadcasting advocates in the 1920s talked about government “censorship,” the term was not abstract — it was a recent fact.
But rather than try to figure out a smarter way to fund public-minded, high-quality broadcasting, the men behind the Radio Broadcast contest decided the real winner should be: Nothing. “For the present, I think it is better to let things ride along as they are,” wrote columnist Zeh Brouck in May 1925.
Things did ride along, straight to direct advertising. Within a few years, huge swathes of the airwaves were the province of Lucky Strikes and Jergen’s Lotion, racial minstrelsy and unbelievable quackery…
… For many happy decades of the 20th century, advertising did make commercial broadcasters a ton of money. But as historians from Robert McChesney to Susan Douglas to Michele Hilmes have pointed out, the “American system” is uniquely unstable, and it leaves public-interest programming — or, at times, any programming at all — hard to sustain.
While researching this piece, I learned I’m not the first writer to notice an anniversary of Radio Broadcast’s contest. Back in 1995, Todd Lappin explored it in Wired. He marveled at how much the nascent Web was following the same chaotic business arc of radio. But he held out hope that things might turn out better. “Perhaps radio wasn’t the right technology. But the Web and the Net may well be,” Lappin wrote. “Our job is to make sure that glorious potential doesn’t get stuffed into yet another tired, old media box.”
In retrospect, that’s a depressing read. But there is something irresistible about the original contest, and the era when all ideas were still up for debate. We’ve had a century of letting things “ride along.” It seems like a good time to open the contest again…
An all-too-timely read: “In 1924, a magazine ran a contest: “Who is to pay for broadcasting and how?” A century later, we’re still asking the same question,” from @bartona104 in @NiemanLab.
* Digg commenter blue_beetle (Anthony Lewis)– now a meme.
###
As we contemplate culture, we might recall that it was on this date in 2007 that two local television helicopters covering a police chase in Phoenix, Arizona collided in air. Pilot Craig Smith and photographer Rick Krolak from KNXV-TV, and pilot Scott Bowerbank and photographer Jim Cox from KTVK were killed; there were no reported casualties on the ground.

“Why do I feel so exercised about what we think of the people of the Middle Ages?”*…

There was more to the period than violence, superstition and ignorance: The Economist on a new book, Medieval Horizons, from Ian Mortimer…
“In public your bottom should emit no secret winds past your thighs. It disgraces you if other people notice any of your smelly filth.” This useful bit of advice for young courtiers in the early 13th century appears in “The Book of the Civilised Man”, a poem by Daniel of Beccles. It is the first English guide to manners.
Ian Mortimer, a historian, argues that this and other popular works of advice that began appearing around the same time represent something important: a growing sense of social self-awareness, self-evaluation and self-control. Why then? Probably because of the revival of glass mirrors in the 12th century, which had disappeared from Europe after the fall of Rome. The mirror made it possible for men and women to see themselves as others did. It confirmed their individuality and inspired a greater sense of autonomy and potential. By 1500 mirrors were cheap, and their impact had spread through society.
Mr. Mortimer sets out to show that the medieval period, from 1000 to 1600, is profoundly misunderstood. It was not a backward and unchanging time marked by violence, ignorance and superstition. Instead, huge steps in social and economic progress were made, and the foundations of the modern world were laid.
The misapprehension came about because people’s notion of progress is so bound up with scientific and technological developments that came later, particularly with the industrial and digital revolutions. The author recounts one claim he has heard: that a contemporary schoolchild (armed with her iPhone) knows more about the world than did the greatest scientist of the 16th century.
Never mind that astronomers such as Copernicus and Galileo knew much more about the stars than most children do today. Could a modern architect (without his computer) build a stone spire like Lincoln Cathedral’s, which is 160 metres (525 feet) tall and was completed by 1311? Between 1000 and 1300 the height of the London skyline quintupled, whereas between 1300 and the completion of the 72-storey Shard in 2010, it only doubled. Inventions, including gunpowder, the magnetic compass and the printing press, all found their way from China to transform war, navigation and literacy.
This led to many “expanding horizons” for Europeans. Travel was one. In the 11th century no European had any idea what lay to the east of Jerusalem or south of the Sahara. By 1600 there had been several circumnavigations of the globe.
Law and order was another frontier. Thanks to the arrival of paper from China in the 12th century and the advent of the printing press in the 1430s, document-creation and record-keeping, which are fundamental to administration, surged. Between 1000 and 1600 the number of words written and printed in England went from about 1m a year to around 100bn. In England, a centralised legal and criminal-justice system evolved rapidly from the 12th century. Violent deaths declined from around 23 per 100,000 in the 1300s to seven per 100,000 in the late 16th century.
Another “horizon” was speed and the sense of urgency that went with it. By 1600 a letter bearing important news could be carried 200 miles in a single day, thanks to people starting to use relays of horses at staging posts. Over the course of the 14th century mechanical clocks were developed, allowing time to be standardised and appointments to be kept.
The period was also marked by growing personal freedom, with the banning of slavery within England by the English church in 1102 and the rapid decline of serfdom after the Black Death of 1348-49, when nearly half the labour force died. Political power expanded to include a growing land and property-owning yeoman class. Whoever thinks the Middle Ages were all darkness has a middling understanding of history’s truths…
Shedding light on the Dark Ages: “Is everything you assumed about the Middle Ages wrong?” (gift link) @TheEconomist on @IanJamesFM.
* “Why do I feel so exercised about what we think of the people of the Middle Ages?…I guess it’s because so many of their voices are ringing vibrantly in my ears – Chaucer’s, Boccaccio’s, Henry Knighton’s, Thomas Walsingham’s, Froissart’s, Jean Creton’s… writers and contemporary historians of the period who seem to me just as individual, just as alive as we are today. We need to get to know these folk better in order to know who we are ourselves.” — Terry Jones (@PythonJones) in The Observer
###
As we look back, we might recall that it was on this date (the feast day of St. Mary Magdalene) in in Middle Ages (more specially, in 1342), that Central Europe’s worst flood ever occurred. Following the passage of a Genoa low, the rivers Rhine, Moselle, Main, Danube, Weser, Werra, Unstrut, Elbe, Vltava, and their tributaries inundated large areas. Many towns such as Cologne, Mainz, Frankfurt am Main, Würzburg, Regensburg, Passau, and Vienna were seriously damaged, with water levels exceeding those of the 2002 European floods. Even the river Eider north of Hamburg flooded the surrounding land; indeed, the affected area extended to Carinthia and northern Italy.

You must be logged in to post a comment.