As the tools in the world around us change, the world– and we– change with them. The onslaught of AI is the change that seems to be grabbing most of our mindshare these days… and with reason. But there are, of course, other changes (in biotech, in materials science, et al.) that are also going to be hugely impactful.
Today, a look at the computing technology stalking up behind AI: quantum computing. As enthusiasts like David Deutsch (author of the quote above) argue, it can have tremendousbenefits, perhaps especially in our ability to model (and thus better understand) our reality.
But quantum computing will, if/when it arrives, also present huge challenges to us as individuals and as societies– perhaps most prominently in its threat to the ways in which we protect our systems and our information: We’ve felt pretty safe for decades, secure in the knowledge that we could lose passwords to phising or hacks, but that it would take the “classical” computers we have 1 billion years to break today’s RSA-2048 encryption. A quantum computer could crack it in as little as a hundred seconds.
The technology has been “somewhere on the horizon” for 30 years… so not something that has seemed urgent to confront. But progress has accelerated; a recent Google paper reports on a programming and architectural breakthrough that greatly reduces the computing resources necessary to break classical cryptography… putting the prospect of “Q-Day” (the point at which quantum computers become powerful enough to break standard encryption methods (RSA, ECC), endangering global digital security) much closer, which would put everything from crypto-wallets to our e-banking accounts at risk.
Some 30 years ago, the mathematician Peter Shor took a niche physics project — the dream of building a computer based on the counterintuitive rules of quantum mechanics — and shook the world.
Shor worked out a way for quantum computers to swiftly solve a couple of math problems that classical computers could complete only after many billions of years. Those two math problems happened to be the ones that secured the then-emerging digital world. The trustworthiness of nearly every website, inbox, and bank account rests on the assumption that these two problems are impossible to solve. Shor’s algorithm proved that assumption wrong.
For 30 years, Shor’s algorithm has been a security threat in theory only. Physicists initially estimated that they would need a colossal quantum machine with billions of qubits — the elements used in quantum calculations — to run it. That estimate has come down drastically over the years, falling recently to a million qubits. But it has still always sat comfortably beyond the modest capabilities of existing quantum computers, which typically have just hundreds of qubits.
However, two different groups of researchers have just announced advances that notably reduce the gap between theoretical estimates and real machines. A star-studded team of quantum physicists at the California Institute of Technology went public with a design for a quantum computer that could break encryption with only tens of thousands of qubits and said that it had formed a company to build the machine. And researchers at Google announced that they had developed an implementation of Shor’s algorithm that is ten times as efficient as the best previous method.
Neither company has the hardware to break encryption today. But the results underscore what some quantum physicists had already come to suspect: that powerful quantum computers may be years away, rather than decades. “If you care about privacy or you have secrets, then you better start looking for alternatives,” said Nikolas Breuckmann, a mathematical physicist at the University of Bristol, who did not work on either of the papers.
While the new results may provide a jolt for the policymakers and corporations that guard our digital infrastructure, they also signal the rapid progress that physicists have made toward building machines that will let them more thoroughly explore the quantum world.
“We’re going to actually do this,” said Dolev Bluvstein, a Caltech physicist and CEO of the new company, Oratomic…
[Wood unpacks the history of the development of the technology and explores the challenges that remain; he concludes…]
… If any group succeeds at building a quantum computer that can realize Shor’s algorithm, it will mark the end an era — specifically, the “Noisy Intermediate Scale Quantum” era, as Preskill dubbed the pre-error-correction period in a 2018 paper. Each researcher has a vision for what to pursue first with a machine in the new “fault-tolerant” era.
[Robert] Huang said he would start by running Shor’s algorithm, just to prove that the device works. After that, he said he would try to use it to speed up machine learning — an application to be detailed in coming work.
Most of the architects building quantum computers, whether at Oratomic or other startups, are physicists at heart. They’re interested in physics, not cryptography. Specifically, they’re interested in all the things a computer fluent in the language of quantum mechanics could teach them about the quantum realm, such as what sort of materials might become superconductors even at warm temperatures. Preskill, for his part, would like to simulate the quantum nature of space-time.
The Caltech group knows it has years of work ahead before any of its dreams have a chance of coming true. But the researchers can’t wait to get started. “Pick a cooler life quest than building the world’s first quantum computer with your friends!” said a jubilant Bluvstein, reached by phone shortly before their paper went live, before rushing off to celebrate…
As we prepare, we might take a moment to appreciate just how vastly and deeply the legacy systems challenged by quantum computing run, recalling that on this date in 1959 Mary Hawes, a computer scientist for the Burroughs Corporation held a meeting of computers users, manufacturers, and academics at the University of Pennsylvania aimed at creating a common business oriented programming language. At the meeting, representative Grace Hopper suggested that they ask the Department of Defense to fund the effort to create such a language. Also attending was Charles Phillips who was director of the Data System Research Staff at the DoD and was excited by the possibility of a common language streamlining their operations. He agreed to sponsor the creation of such a language. This was the genesis of what would eventually become the COBOL language.
To this day COBOL is still the most common programming language used in business, finance, and administrative systems for companies and governments, primarily on mainframe systems, with around 200 billion lines of code still in production use… all of which are in question and/or at risk in a world of quantum computing.
In 1967, Jimi Hendrix’s manager, Chas Chandler arranged for Jimi to meet Cream…
There was a particular night when Cream allowed Jimi to join them for a jam at the Regent Street Polytechnic in central London. Meeting Clapton had been among the enticements Chandler had used to lure Hendrix to Britain: “Hendrix blew into a version of [Howlin’ Wolf’s] ‘Killing Floor’,” recalls [Tony] Garland, “and plays it at breakneck tempo, just like that – it stopped you in your tracks.” [Keith] Altham recalls Chandler going backstage after Clapton left in the middle of the song “which he had yet to master himself”; Clapton was furiously puffing on a cigarette and telling Chas: “You never told me he was that fucking good.” – source
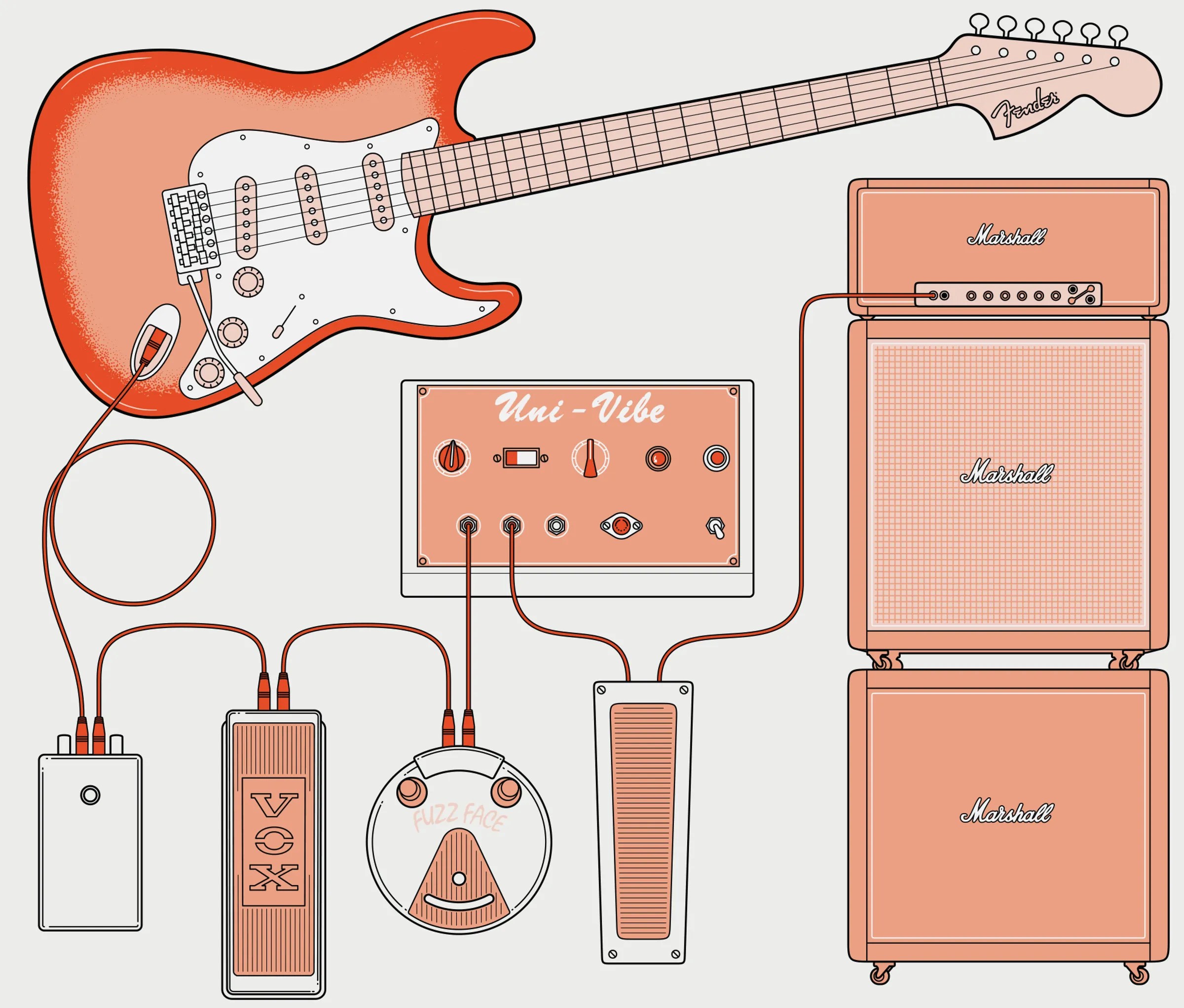
Hendrix’s extraodinary virtuosity has, altogether justly, gotten a great deal of attention; less well noted, his incredible mastery of the technology of music making, recording, and performance. Rohan Puranik explains…
3 February 1967 is a day that belongs in the annals of music history. It’s the day that Jimi Hendrix entered London’s Olympic Studios to record a song using a new component. The song was “Purple Haze,” and the component was the Octavia guitar pedal, created for Hendrix by sound engineer Roger Mayer. The pedal was a key element of a complex chain of analog elements responsible for the final sound, including the acoustics of the studio room itself. When they sent the tapes for remastering in the United States, the sounds on it were so novel that they included an accompanying note explaining that the distortion at the end was not malfunction but intention. A few months later, Hendrix would deliver his legendary electric guitar performance at the Monterey International Pop Festival.
“Purple Haze” firmly established that an electric guitar can be used not just as a stringed instrument with built-in pickups for convenient sound amplification, but also as a full-blown wave synthesizer whose output can be manipulated at will. Modern guitarists can reproduce Hendrix’s chain using separate plug-ins in digital audio workstation software, but the magic often disappears when everything is buffered and quantized. I wanted to find out if a more systematic approach could do a better job and provide insights into how Hendrix created his groundbreaking sound.
My fascination with Hendrix’s Olympic Studios’ performance arose because there is a “Hendrix was an alien” narrative surrounding his musical innovation—that his music appeared more or less out of nowhere. I wanted to replace that narrative with an engineering-driven account that’s inspectable and reproducible—plots, models, and a signal chain from the guitar through the pedals that you can probe stage by stage…
[And probe it Puranik does– fascinatingly, stage by stage…]
… Hendrix didn’t speak in decibels and ohm values, but he collaborated with engineers who did—Mayer and Kramer—and iterated fast as a systems engineer. Reframing Hendrix as an engineer doesn’t diminish the art. It explains how one person, in under four years as a bandleader, could pull the electric guitar toward its full potential by systematically augmenting the instrument’s shortcomings for maximum expression.
As we plug in, we might send well-connected birthday greetings to another wizard with wires, Geoff Tootill; he was born on this date in 1922. An electronic engineer and computer scientist, he worked (with Freddie Williams and Tom Kilburn) to design a computer memory. To that end they built the first electronic stored-program computer— the Manchester Baby— at the University of Manchester in 1948.
The Baby was not intended to be a practical computing engine, but was instead designed as a testbed for the Williams tube, the first truly random-access memory. Nonethless, Baby worked: Alan Turing moved to Manchester to use it, and the following year, it inspired the Ferranti Mark 1, the world’s first commercially available electronic general-purpose stored-program digital computer.
One punctuation mark in particular is having a moment… a not-altogether-welcome one…
Of the many tips and tricks people are coming up with to determine whether a piece of writing has been written with a little help from AI, the world seems to have homed in on the use of one particular punctuation mark: the em dash.
Though some writers have rushed in to defend the dash — the overuse of which sits alongside pizza glue and bluebberrygate in the pantheon of things people laugh at AI about — perhaps a key reason the prevalence of the punctuation mark seems so bot-like to readers is that, as writers, Americans hardly use it.
Indeed, per a recent YouGov survey, dashes are some of the least used pieces of punctuation in Americans’ arsenals, ranking just ahead of colons and semicolons, per the poll.
As you might imagine, the survey revealed that American adults who describe themselves as “good” or “very good” writers are more likely to use the rarer forms of punctuation on the list. However, for the majority of Americans, marks like the semicolon and the em dash remain mostly reserved for esteemed authors and English teachers… or those who aren’t above enlisting a chatbot for a little help to jazz up their communications.
Interestingly, the vast majority of Americans said they do little writing outside of sending texts and emails, with journaling, nonfiction and fiction writing, and other forms of creative or academic writing all falling by the wayside in 2025, according to YouGov’s research…
As we muse on marks, we might that it was on this date in 1956 that Fortran was introduced to the world. A third-generation, compiled, imperative computer programming language that is especially suited to numeric computation and scientific computing. Developed by an IBM team led by John Backus, it became the go-to language for high-performance computing and is used for programs that benchmark and rank the world’s fastest supercomputers.
In a 1979 interview with Think, the IBM employee magazine, Backus explained Fortran’s origin: “Much of my work has come from being lazy. I didn’t like writing programs, and so, when I was working on the IBM 701, writing programs for computing missile trajectories, I started work on a programming system to make it easier to write programs.”
To the item at the top, it’s worth noting that Fortran is a language with four uses for the dash– subtraction operator, negative sign, line continuation symbol, and range separator (in data processing)– but no em dash.
For a piece of Fortran’s pre-history, see here; and for an important extension, see here.
For millennia, simple forms of record-keeping have been used as ways to keep track of debt, to substitute for the contemporaneous conveyance of specie, or to accommodate the future settlement and netting of debts. In England, tally sticks were regularly used. From Paolo Zannoni, an excerpt from his book, Money and Promises, via Richard Vague and his invaluable Delancey Place…
A tally is usually a stick, or a bone, or a piece of ivory — some kind of artefact — that is used to record information. Palaeolithic tallies include the Lembombo bone, found in the Lembombo Mountains in southern Africa, reported to date from around 44,000 BC; the Ishango bone, which consists of the fibula of a baboon, from the Democratic Republic of the Congo (the former Belgian Congo), thought to be 20,000 years old; and the so-called Wolf bone, discovered in Czechoslovakia during excavations at Vestonice, Moravia, in the 1930s, and estimated to be around 30,000 years old. Marked with notches and symbols, these tallies are ancient recording devices, means of data storage and communication. Not merely artefacts, they are important historical documents.
In England, from around the twelfth century, and for over 600 years, tallies became important financial instruments, a key part of public finance and an answer to a perennial problem for money-lenders, merchants and those involved in commerce and trade: how to both facilitate and record the exchange of goods, services and commodities. Reading these English tallies, understanding their history and their changing use, provides us with an understanding not only of the nature of individual financial transactions during the late medieval and early modern period, but also of the development of banking practices in England and its relationship to the English state.
Usually made of willow or hazelwood, tallies were used to record the key information of a financial exchange. The name of the parties involved, the specific trade and the date were written on each side of a stick. Notches of different sizes — which stood for pounds, shillings, and pence — were also cut on both sides. Then the stick was split in two along its length, creating a unique jagged edge; only those two pieces could ever fit perfectly together again. When someone presented one side as proof of a transaction, the parties could check for the right fit.
The potential uses for such a simple tool are obvious.
To begin with: an example of the early use of tallies as a record of debt repayment. John D’Abernon was the Sheriff of Surrey. His portrait in brass, in Stoke D’Abernon Church, Cobham, shows him as a knight in full armour, wielding a broadsword.
When he died, D’Abernon left his title, possessions and debts to his son, also named John. In 1293, we know that John D’Abernon gave two pounds and ten shillings to the Exchequer to pay a fine on behalf of his father. How do we know? Because at the time of payment, the official tally cutter made a series of notches on a stick: two cuts for the two pounds and one smaller notch for the ten shillings. The stick was then split, with the longer end going to John, and the shorter end staying with the Exchequer. The following words were inscribed on both sides: ‘From John D’Abernon for his father’s fine’ and ‘XXI year of the King Edward’.
John could thus prove to anyone that he had paid the fine of his father — simple and convenient.
Tallies also enabled the functioning of the tax system in medieval England, which was a rather more complex affair. The process took months to complete. It worked roughly like this. Tax receivers collected revenues from the King’s subjects at Easter. They then passed them on to the Exchequer, which completed an audit in late September or early October. At the time, the Exchequer had two branches: the Lower and the Higher. The Lower Exchequer received and disbursed the revenues. The Higher Exchequer audited the process. They used tallies to track who had paid whom. As soon as the Lower Exchequer received the revenues, the tally cutter recorded the payment on the tally and split the stick. The tax receiver — the debtor — got the longer part, called the ‘stock’. The Exchequer — the creditor — kept the short end of the stick, called the ‘foil’. And once a year, at Michaelmas, the Higher Exchequer audited the whole process by matching stocks and foils. The stock was the proof that the collector had not merely pocketed the tax revenues.
Over time, both the use and appearance of the tallies began to change: in the early years, tallies were 3 to 5 inches long; later, they grew to be 1 to 2 feet long, and sometimes much longer. More money meant more notches; more notches, in turn, required longer sticks. One of the last issues of tallies made by the English Exchequer was in 1729, for £50,000: the tally is a whopping 8 feet, 5 inches long, visible proof of the growth of public spending, taxation and inflation.
As the appearance of the tallies changed, so too did their uses. Inside the Exchequer, they served as receipts for money paid by taxpayers. Outside the Exchequer, they began to be put to entirely different purposes.
The business of the Exchequer simply could not work without the tally sticks. They were essential for auditing and controlling public finances, which obviously made them excellent collateral for a loan.
The tally was not a mere generic promise to pay, but a strong, unique claim on the proceeds of the Exchequer’s revenue stream. It identified the cashflow and the individual in charge of paying; the creditor gave the stock to the indicated tax receiver to get coins from a specific revenue stream, and a lender was sure to get his coins sooner or later. The humble English tally stick was therefore ripe to become a veritable public debt security, not merely a receipt. They functioned just like paper public debt securities, except instead of being written on paper, the transactions were instantiated and inscribed on sticks.
To take an early example: Richard de la Pole was a merchant who traded wool, wine and corn with France and central Europe in the early 1300s. He had a reputation for using debts aggressively to grow his business, which appealed to King Edward III and his advisors, who thought they might be able to make use of his skills. So, they appointed him Royal Butler. The job of butler was to supply all sorts of goods — food, wine and arms — to the royal household and to the army. We know that in 1328 Richard bought some wine from the French. As a good businessman, as Royal Butler, did he pay for the wine in coins? He did not. Rather, in order to pay the bill, the Lower Exchequer cut eight tallies, which were addressed to the collectors of taxes for West Riding in Yorkshire, listing the tax revenues earmarked to settle the debt. The Lower Exchequer gave the foils — one half of all the eight tallies — to Richard, who handed them to the merchants who sold him the wine. The merchants then exchanged the tallies with coins from the taxes paid in West Riding, and finally, a few months later, the Higher Exchequer called upon the tax receivers to account for the shortfall of cash, whereupon they presented the eight foils, which had been first given to Richard, as proof of the payments made.
To be clear: unlike coins, tallies did not actually settle debt. By accepting a foil, a vendor was effectively agreeing to a delayed payment from the Exchequer; the tally was a kind of guarantee that they would get coins. For the state, meanwhile, the tally was a convenient way to borrow from its suppliers, or a form of what we would now call vendor financing — the citizens and merchants who sold goods and services for tallies were effectively financing the state, in much the same way as those who lent actual coins to the Exchequer…
As money grows in importance, a new struggle is beginning for the control of it in the coming century. We are likely to see a prolonged era of competition during which many kinds of money will appear, proliferate, and disappear in rapidly crashing waves. In the quest to control the new money, many contenders are struggling to become the primary money institution of the new era…
* Adam Smith
###
As we contemplate currency, we might recall that it was on this date in 1888 that William Seward Burroughs of St. Louis, Missouri, received patents on four adding machine applications (No. 388,116-388,119), the first U.S. patents for a “Calculating-Machine” that the inventor would continue to improve and successfully market– largely to businesses and financial institutions. The American Arithmometer Corporation of St. Louis, later renamed The Burroughs Corporation, became– with IBM, Sperry, NCR, Honeywell, and others– a major force in the development of computers. Burroughs also gifted the world his grandson, Beat icon William S. Burroughs.
As scholars like Robert Gordon and Tyler Cowan have begun to call out a slowing of progress and growth in the U.S., others are beginning to wonder if “innovation clusters” like Silicon Valley are still advantageous. For example, Brian J. Asquith…
In 2011, the economist Tyler Cowen published The Great Stagnation, a short treatise with a provocative hypothesis. Cowen challenged his audience to look beyond the gleam of the internet and personal computing, arguing that these innovations masked a more troubling reality. Cowen contended that, since the 1970s, there has been a marked stagnation in critical economic indicators: median family income, total factor productivity growth, and average annual GDP growth have all plateaued…
In the years since the publication of the Great Stagnation hypothesis, others have stepped forward to offer support for this theory. Robert Gordon’s 2017 The Rise and Fall of American Growth chronicles in engrossing detail the beginnings of the Second Industrial Revolution in the United States, starting around 1870, the acceleration of growth spanning the 1920–70 period, and then a general slowdown and stagnation since about 1970. Gordon’s key finding is that, while the growth rate of average total factor productivity from 1920 to 1970 was 1.9 percent, it was just 0.6 percent from 1970 to 2014, where 1970 represents a secular trend break for reasons still not entirely understood. Cowen’s and Gordon’s insights have since been further corroborated by numerous research papers. Research productivity across a variety of measures (researchers per paper, R&D spending needed to maintain existing growth rates, etc.) has been on the decline across the developed world. Languishing productivity growth extends beyond research-intensive industries. In sectors such as construction, the value added per worker was 40 percent lower in 2020 than it was in 1970. The trend is mirrored in firm productivity growth, where a small number of superstar firms see exceptionally strong growth and the rest of the distribution increasingly lags behind.
A 2020 article by Nicholas Bloom and three coauthors in the American Economic Review cut right to the chase by asking, “Are Ideas Getting Harder to Find?,” and answered its own question in the affirmative.6 Depending on the data source, the authors find that while the number of researchers has grown sharply, output per researcher has declined sharply, leading aggregate research productivity to decline by 5 percent per year.
This stagnation should elicit greater surprise and concern because it persists despite advanced economies adhering to the established economics prescription intended to boost growth and innovation rates: (1) promote mass higher education, (2) identify particularly bright young people via standardized testing and direct them to research‑intensive universities, and (3) pipe basic research grants through the university system to foster locally-driven research and development networks that supercharge productivity…
…
… the tech cluster phenomenon stands out because there is a fundamental discrepancy between how the clusters function in practice versus their theoretical contributions to greater growth rates. The emergence of tech clusters has been celebrated by many leading economists because of a range of findings that innovative people become more productive (by various metrics) when they work in the same location as other talented people in the same field. In this telling, the essence of innovation can be boiled down to three things: co-location, co-location, co-location. No other urban form seems to facilitate innovation like a cluster of interconnected researchers and firms.
This line of reasoning yields a straightforward syllogism: technology clusters enhance individual innovation and productivity. The local nature of innovation notwithstanding, technologies developed within these clusters can be adopted and enjoyed globally. Thus, while not everyone can live in a tech cluster, individuals worldwide benefit from new advances and innovations generated there, and some of the outsized economic gains the clusters produce can then be redistributed to people outside of the clusters to smooth over any lingering inequalities. Therefore, any policy that weakens these tech clusters leads to a diminished rate of innovation and leaves humanity as a whole poorer.
Yet the fact that the emergence of the tech clusters has also coincided with Cowen’s Great Stagnation raises certain questions. Are there shortcomings in the empirical evidence on the effects of the tech clusters? Does technology really diffuse across the rest of the economy as many economists assume? Do the tech clusters inherently prioritize welfare-enhancing technologies? Is there some role for federal or state action to improve the situation? Clusters are not unique to the postwar period: Detroit famously achieved a large agglomeration economy based on automobiles in the early twentieth century, and several authors have drawn parallels between the ascents of Detroit and Silicon Valley. What makes today’s tech clusters distinct from past ones? The fact that the tech clusters have not yielded the same society-enhancing benefits that they once promised should invite further scrutiny…
See also: Brad DeLong, on comments from Eric Schmidt: “That an externality market failure is partly counterbalanced and offset by a behavioral-irrationality-herd-mania cognitive failure is a fact about the world. But it does not mean that we should not be thinking and working very hard to build a better system—or that those who profit mightily from herd mania on the part of others should feel good about themselves.”
As we contemplate co-location, we might recall that it was on this date in 1956 that a denizen of one of America’s leading tech/innovation hubs, Jay Forrester at MIT [see here and here], was awarded a patent for his coincident current magnetic core memory (Patent No. 2,736,880). Forrester’s invention, a “multicoordinate digital information storage device,” became the standard memory device for digital computers until supplanted by solid state (semiconductor) RAM in the mid-1970s.










You must be logged in to post a comment.